$ wget http://download.redis.io/releases/redis-4.0.0.tar.gz $ tar xzvf redis-4.0.0.tar.gz -C /usr/local/ $ cd /usr/local/redis-4.0.0 $ make $ make test $ make install # 程序会自动执行: # mkdir -p /usr/local/bin # cp -pf redis-server /usr/local/bin # cp -pf redis-benchmark /usr/local/bin # cp -pf redis-cli /usr/local/bin # cp -pf redis-check-dump /usr/local/bin # cp -pf redis-check-aof /usr/local/bin
测试make test报错
1 2 3
$ make test You need tcl 8.5 or newer in order to run the Redis test make: *** [test] Error 1
这个是需要安装tcl
1 2 3 4 5 6
wget http://downloads.sourceforge.net/tcl/tcl8.6.1-src.tar.gz sudo tar xzvf tcl8.6.1-src.tar.gz -C /usr/local/ cd /usr/local/tcl8.6.1/unix/ sudo ./configure sudo make sudo make install
通过EPEL源安装
源安装问题在于不能安装最新,或者指定Redis版本。
1
yum --enablerepo=epel -y install redis
如果没有安装源,通过下面方式安装源。
1 2
cd /etc/yum.repos.d/ rpm -Uvh http://download.fedoraproject.org/pub/epel/6/x86_64/epel-release-6-8.noarch.rpm
yum --enablerepo=epel info redis # Loaded plugins: fastestmirror # Loading mirror speeds from cached hostfile # * base: centos.ustc.edu.cn # * epel: mirrors.tuna.tsinghua.edu.cn # * extras: centos.ustc.edu.cn # * updates: mirrors.zju.edu.cn # Available Packages # Name : redis # Arch : x86_64 # Version : 2.4.10 # Release : 1.el6 # Size : 213 k # Repo : epel/x86_64 # Summary : A persistent key-value database # URL : http://redis.io # License : BSD # Description : Redis is an advanced key-value store. It is similar to memcached but the data # : set is not volatile, and values can be strings, exactly like in memcached, but # : also lists, sets, and ordered sets. All this data types can be manipulated with # : atomic operations to push/pop elements, add/remove elements, perform server # : side union, intersection, difference between sets, and so forth. Redis supports # : different kind of sorting abilities.
WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add ‘vm.overcommit_memory = 1’ to /etc/sysctl.conf and then reboot or run the command ‘sysctl vm.overcommit_memory=1’ for this to take effect.
K Keyspace events, published with __keyspace@<db>__ prefix. E Keyevent events, published with __keyevent@<db>__ prefix. g Generic commands (non-type specific) like DEL, EXPIRE, RENAME, ... $ String commands l List commands s Set commands h Hash commands z Sorted set commands x Expired events (events generated every time a key expires) e Evicted events (events generated when a key is evicted for maxmemory) A Alias for g$lshzxe, so that the "AKE" string means all the events.
-A INPUT -m state --state NEW -m tcp -p tcp --dport 6379 -j ACCEPT
修改配置文件
Redis protected-mode 是3.2 之后加入的新特性,在Redis.conf的注释中,我们可以了解到,他的具体作用和启用条件。可以在 sudo vi /etc/redis.conf 中编辑,修改配置文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# Protected mode is a layer of security protection, in order to avoid that # Redis instances left open on the internet are accessed and exploited. # # When protected mode is on and if: # # 1) The server is not binding explicitly to a set of addresses using the # "bind" directive. # 2) No password is configured. # # The server only accepts connections from clients connecting from the # IPv4 and IPv6 loopback addresses 127.0.0.1 and ::1, and from Unix domain # sockets. # # By default protected mode is enabled. You should disable it only if # you are sure you want clients from other hosts to connect to Redis # even if no authentication is configured, nor a specific set of interfaces # are explicitly listed using the "bind" directive. protected-mode yes
(error) DENIED Redis is running in protected mode because protected mode is enabled, no bind address was specified, no authentication password is requested to clients. In this mode connections are only accepted from the lookback interface. If you want to connect from external computers to Redis you may adopt one of the following solutions: 1) Just disable protected mode sending the command'CONFIG SET protected-mode no' from the loopback interface by connecting to Redis from the same host the server is running, however MAKE SURE Redis is not publicly accessible from internet if you do so. Use CONFIG REWRITE to make this change permanent. 2) Alternatively you can just disable the protected mode by editing the Redis configuration file, and setting the protected mode option to 'no', and then restarting the server. 3) If you started the server manually just for testing, restart it with the --portected-mode no option. 4) Setup a bind address or an authentication password. NOTE: You only need to do one of the above things in order for the server to start accepting connections from the outside.
# Scanning the entire keyspace to find biggest keys as well as # average sizes per key type. You can use -i 0.1 to sleep 0.1 sec # per 100 SCAN commands (not usually needed).
[00.00%] Biggest string found so far 'asdf.js' with 3 bytes [00.00%] Biggest string found so far 'wabg-tokeneyJhbGciOiJIUzI1NiJ9.NA.UGGRiB2I42rP-33cIMrcoPub7AzHgDlqHacAKFw1pfE' with 328 bytes [00.00%] Biggest string found so far 'wabg-token-province' with 231042 bytes
-------- summary -------
Sampled 4 keys in the keyspace! Total key length in bytes is 180 (avg len 45.00)
Biggest string found 'wabg-token-province' has 231042 bytes
4 strings with 231819 bytes (100.00% of keys, avg size 57954.75) 0 lists with 0 items (00.00% of keys, avg size 0.00) 0 sets with 0 members (00.00% of keys, avg size 0.00) 0 hashs with 0 fields (00.00% of keys, avg size 0.00) 0 zsets with 0 members (00.00% of keys, avg size 0.00)
################################## INCLUDES ################################### #这在你有标准配置模板但是每个redis服务器又需要个性设置的时候很有用。 # include /path/to/local.conf # include /path/to/other.conf
################################ GENERAL #####################################
#当从库同主机失去连接或者复制正在进行,从机库有两种运行方式:1) 如果slave-serve-stale-data设置为yes(默认设置),从库会继续响应客户端的请求。2) 如果slave-serve-stale-data设置为no,除去INFO和SLAVOF命令之外的任何请求都会返回一个错误”SYNC with master in progress”。 slave-serve-stale-data yes
#是否使用socket方式复制数据。目前redis复制提供两种方式,disk和socket。如果新的slave连上来或者重连的slave无法部分同步,就会执行全量同步,master会生成rdb文件。有2种方式:disk方式是master创建一个新的进程把rdb文件保存到磁盘,再把磁盘上的rdb文件传递给slave。socket是master创建一个新的进程,直接把rdb文件以socket的方式发给slave。disk方式的时候,当一个rdb保存的过程中,多个slave都能共享这个rdb文件。socket的方式就的一个个slave顺序复制。在磁盘速度缓慢,网速快的情况下推荐用socket方式。 repl-diskless-sync no
# 设置1或另一个设置为0禁用这个特性。 # Setting one or the other to 0 disables the feature. # By default min-slaves-to-write is set to 0 (feature disabled) and # min-slaves-max-lag is set to 10.
############################## APPEND ONLY MODE ############################### #默认redis使用的是rdb方式持久化,这种方式在许多应用中已经足够用了。但是redis如果中途宕机,会导致可能有几分钟的数据丢失,根据save来策略进行持久化,Append Only File是另一种持久化方式,可以提供更好的持久化特性。Redis会把每次写入的数据在接收后都写入 appendonly.aof 文件,每次启动时Redis都会先把这个文件的数据读入内存里,先忽略RDB文件。 appendonly no
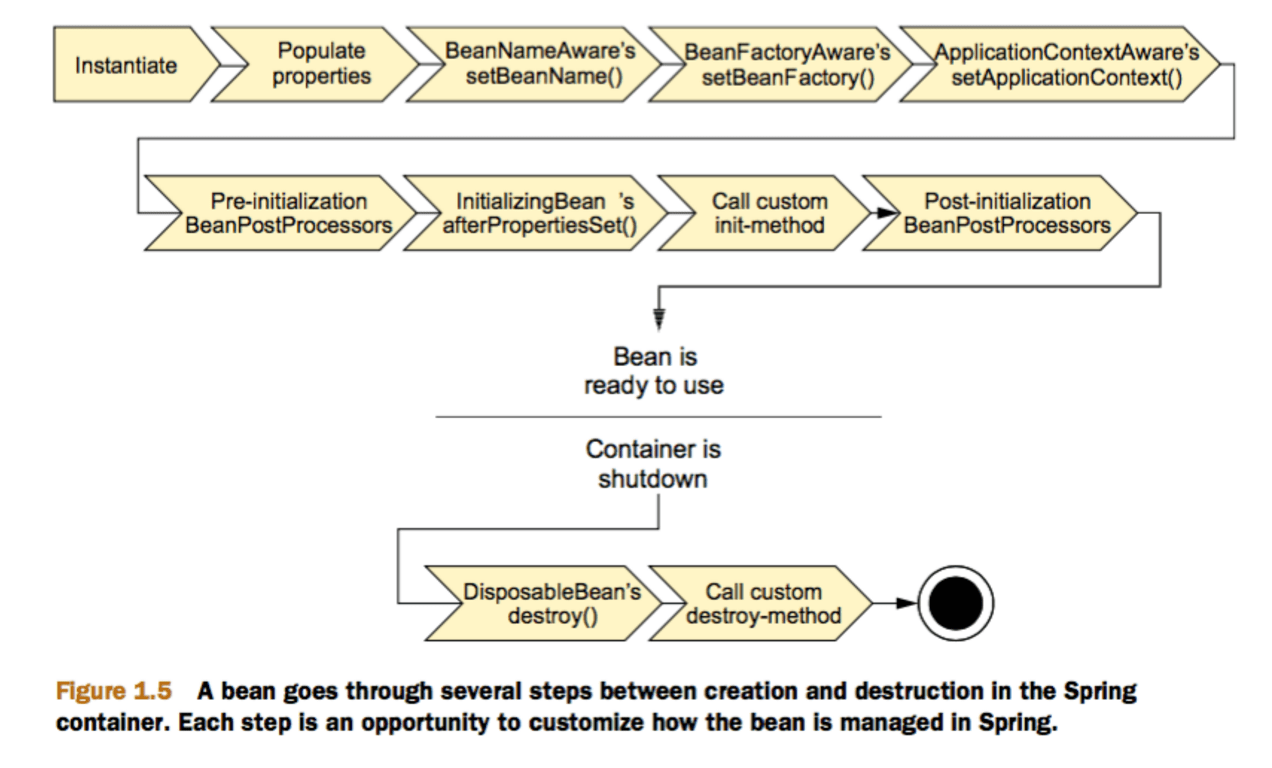
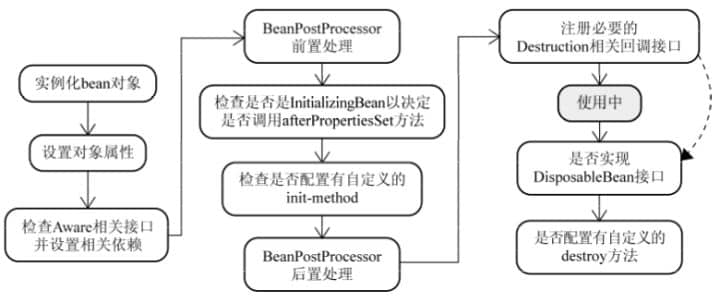
在 Spring 中,那些组成应用程序的主体及由 Spring IOC 容器所管理的对象,被称之为 bean。简单地讲,bean 就是由 IOC 容器初始化、装配及管理的对象,除此之外,bean 就与应用程序中的其他对象没有什么区别了。而 bean 的定义以及 bean 相互间的依赖关系将通过配置元数据来描述。
LifeBean()构造函数 this is init of lifeBean com.bean.LifeBean@573f2bb1 LifeBean()构造函数 this is init of lifeBean com.bean.LifeBean@5ae9a829 …… this is destory of lifeBean com.bean.LifeBean@573f2bb1