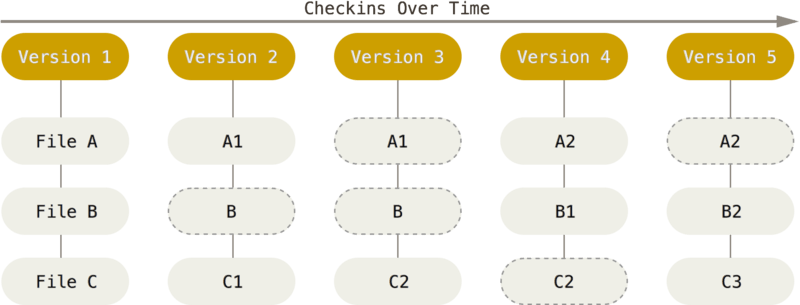
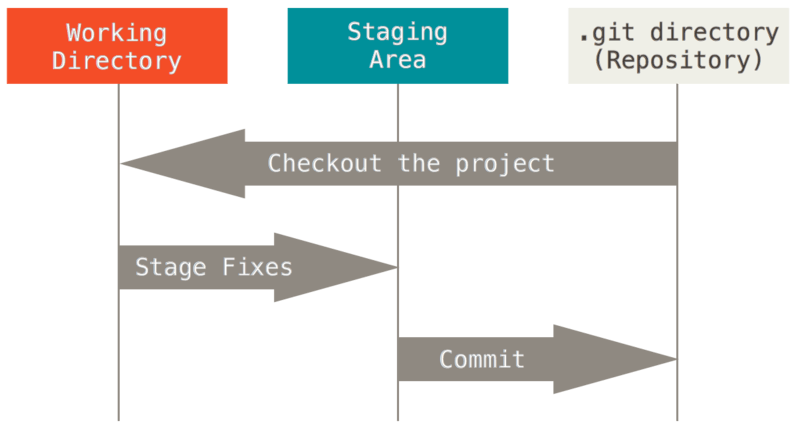
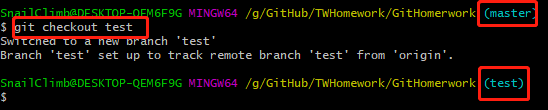
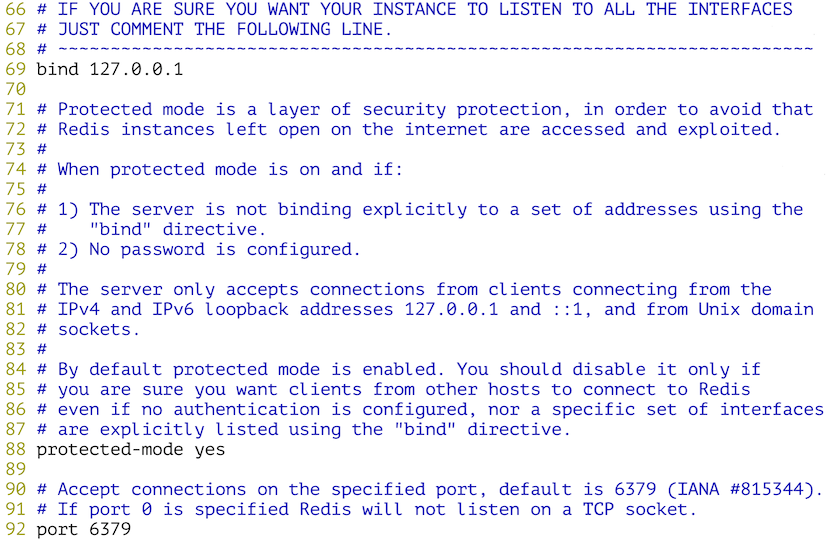
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
| >
> db.students.insert({stuid: 1001, name: '骆昊', age: 38})
WriteResult({ "nInserted" : 1 })
>
> db.students.save({stuid: 1002, name: '王大锤', tel: '13012345678', gender: '男'})
WriteResult({ "nInserted" : 1 })
>
> db.students.find()
{ "_id" : ObjectId("5b13c72e006ad854460ee70b"), "stuid" : 1001, "name" : "骆昊", "age" : 38 }
{ "_id" : ObjectId("5b13c790006ad854460ee70c"), "stuid" : 1002, "name" : "王大锤", "tel" : "13012345678", "gender" : "男" }
>
> db.students.update({stuid: 1001}, {'$set': {tel: '13566778899', gender: '男'}})
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
>
> db.students.update({stuid: 1003}, {'$set': {name: '白元芳', tel: '13022223333', gender: '男'}}, upsert=true)
WriteResult({
"nMatched" : 0,
"nUpserted" : 1,
"nModified" : 0,
"_id" : ObjectId("5b13c92dd185894d7283efab")
})
>
> db.students.find().pretty()
{
"_id" : ObjectId("5b13c72e006ad854460ee70b"),
"stuid" : 1001,
"name" : "骆昊",
"age" : 38,
"gender" : "男",
"tel" : "13566778899"
}
{
"_id" : ObjectId("5b13c790006ad854460ee70c"),
"stuid" : 1002,
"name" : "王大锤",
"tel" : "13012345678",
"gender" : "男"
}
{
"_id" : ObjectId("5b13c92dd185894d7283efab"),
"stuid" : 1003,
"gender" : "男",
"name" : "白元芳",
"tel" : "13022223333"
}
>
> db.students.find({stuid: {'$gt': 1001}}).pretty()
{
"_id" : ObjectId("5b13c790006ad854460ee70c"),
"stuid" : 1002,
"name" : "王大锤",
"tel" : "13012345678",
"gender" : "男"
}
{
"_id" : ObjectId("5b13c92dd185894d7283efab"),
"stuid" : 1003,
"gender" : "男",
"name" : "白元芳",
"tel" : "13022223333"
}
>
> db.students.find({stuid: {'$gt': 1001}}, {_id: 0, name: 1, tel: 1}).pretty()
{ "name" : "王大锤", "tel" : "13012345678" }
{ "name" : "白元芳", "tel" : "13022223333" }
>
> db.students.find({'$or': [{name: '骆昊'}, {tel: '13022223333'}]}, {_id: 0, name: 1, tel: 1}).pretty()
{ "name" : "骆昊", "tel" : "13566778899" }
{ "name" : "白元芳", "tel" : "13022223333" }
>
> db.students.find().skip(1).limit(1).pretty()
{
"_id" : ObjectId("5b13c790006ad854460ee70c"),
"stuid" : 1002,
"name" : "王大锤",
"tel" : "13012345678",
"gender" : "男"
}
>
> db.students.find({}, {_id: 0, stuid: 1, name: 1}).sort({stuid: -1})
{ "stuid" : 1003, "name" : "白元芳" }
{ "stuid" : 1002, "name" : "王大锤" }
{ "stuid" : 1001, "name" : "骆昊" }
>
> db.students.ensureIndex({name: 1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
>
|